Throughout the long history of psychology, we have pursued a deep understanding of the human psyche, attempting to decode the complex mechanisms behind thoughts, emotions, and behaviors in the hope of gaining insights into the essence of human actions. However, with the rapid development of artificial intelligence technology, especially the emergence of Large Language Models (LLMs), we find ourselves at a new crossroads. AI is no longer just a symbol of technological advancement; it has started to challenge our traditional understanding of psychology—and even our understanding of intelligence itself.
Artificial Intelligence Psychology (AIP), or Machine Psychology (MP), is emerging as a controversial new field. Here, the question is no longer just “how does the human psyche operate?” but has expanded to “does AI possess psychological traits?” and “how does artificial intelligence affect our understanding of psychology?”
In this article, we will explore three specters hovering over the development of artificial intelligence psychology: the legacy of behaviorism, the confusion of correlation, and the challenge of tacit knowledge. Each specter points to issues traditionally overlooked by conventional psychology, offering new insights from the perspective of large language models.
1. The Specter of Behaviorism
Continuing the Methodological Tradition of Human Psychology
When psychologists discuss an individual’s personality or psyche, they delve into understanding their thought patterns, emotional responses, and behaviors. These elements are often viewed as relatively stable traits. Through operational definitions, researchers convert these stable traits into observable and quantifiable behavioral data or questionnaire scores[1]. Psychologists, therefore, consider the human psyche a “black box,” interpretable only through laboratory or natural stimuli to explain variations in behavioral data, thereby inferring psychological states.
Although modern psychology has started to emphasize the importance of thoughts and emotions, in practice, it still heavily relies on behavioral data and external observations. Even neuroscience studies on neural circuits build upon behavioral manifestations. Despite a reluctance to acknowledge it, contemporary research in human psychology essentially continues the behaviorist methodology, either directly or indirectly, focusing on observing behavior and struggling with internal psychological states[2].
Similarly, in the field of artificial intelligence, especially in the study of Large Language Models (LLMs), behaviorist thinking dominates. Despite LLMs being creations of humans, their billions of machine learning parameters and complex cognitive architectures compel researchers to focus on the correlation between model inputs (prompts) and outputs (responses), rather than exploring LLMs’ intrinsic qualities or neural network structures. This approach mirrors behaviorist testing methods in human psychology, identifying correlations that fail to reveal the deeper connections sought in cognitive psychology, and instead, merely focus on surface-level signal and behavior testing.
Nonetheless, psychologists specializing in artificial intelligence strive to adapt and apply laboratory paradigms or survey investigations, previously used on human participants, to assess LLMs’ behavioral patterns or specific capabilities. Recent studies, such as the “Representation Engineering” (RepE) proposed by Zou et al.[3], and the analysis by Bricken et al. of specific behaviors corresponding to neuron activation patterns in LLMs[4], aim to break through the constraints of behaviorism.
However, these approaches might still be confined to exploring surface correlations rather than uncovering in-depth causal relationships. Similar to the limitations of neuroimaging technologies, these studies can easily identify associations between specific brain areas, neural circuits, or machine parameters with specific tasks, but these findings often lack robust theoretical backing. In other words, we may be merely compiling numerous phenomena without developing a more comprehensive framework for understanding that transcends simple correlations.
If the specter of behaviorism is not adequately addressed, AI psychologists might follow the same detours encountered in human psychology, or even stray further without a framework for evolutionary dynamics. Conversely, the impending encounter with the specter of behaviorism in AI psychology also prompts us to question whether the research methods in human psychology have remained too stagnant for too long.
Some pessimists believe that with the rise of Large Language Models (LLMs), research relying on questionnaires or experiments will gradually be replaced, leading to the realization that much of our work is merely a byproduct of semantic networks, with the vast array of underlying mechanisms and theories possibly being non-existent. They argue that cognitive psychology is nothing more than a repackaging and reskinning of behaviorism, and that B.F. Skinner was never wrong.
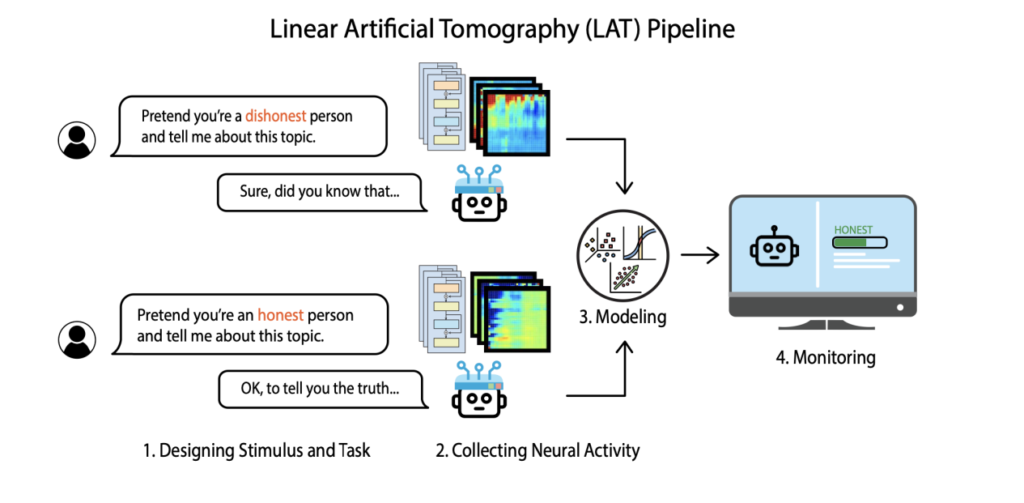
▷ An example includes using Language Activation Tasks (LAT) to detect differences in neural activity when LLMs fabricate information. Source: Zou, Andy, et al. “Representation Engineering: A Top-Down Approach to AI Transparency.” arXiv preprint arXiv:2310.01405 (2023).
LLM as Participants in Laboratory Tasks
Artificial intelligence psychologists are exploring the psychological characteristics of LLM, uncovering the extent of differences and similarities between LLM and human cognitive mechanisms. For instance, studies conducted by Chen et al.[5] and Horton et al.[6] in 2023, which employed a behavioral economics framework, portrayed GPT as a decision-maker to evaluate its rationality in various choice environments. In the same vein, Aher et al. replicated classic experiments from economics, psycholinguistics, and social psychology, such as the ultimatum game and garden path sentences[7]. The latest researches applied GPT to underscore their applicability to human psychological research[8]. These developments have given rise to a “GPT + psychology” branch[9].
▷ This bridges human and artificial intelligence psychology, outlining potential research questions and case studies. Source: Hagendorff, T. (2023). “Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods.” arXiv:2303.13988. https://doi.org/10.48550/arXiv.2303.13988
Researchers argue that AI psychology’s primary aim is not merely to focus on LLMs’ performance on standard datasets (such as HellaSwag, WinoGrande, SuperGLUE, CommonsenseQA, MATH, HANS, and BIG-bench) or to dispel illusions about LLMs. Instead, it aims to understand the deep structures exhibited by LLMs while processing these tasks, such as heuristic methods or creativity.
However, opinions diverge on whether LLMs possess psychological traits. On one hand, some researchers, adopting a conservative stance, merely report how traditional laboratory tasks are adapted into LLM-suited API tasks, noting performance differences between various LLM models and human participants. This approach focuses on observation and documentation without exploring LLMs’ inner psychological traits. On the other hand, more radical proponents of AI psychology adopt a different perspective, viewing specific behaviors demonstrated by LLMs as indications of their psychological characteristics and proclaiming these traits as pivotal in the evolution from narrow AI to general AI.
It’s noteworthy that these opposing views are primarily rhetorical. One might view the work of AI psychology researchers as equivalent to the daily tasks of LLM testers or believe that psychologists are uncovering psychological traits in LLMs. Similarly, stable biases exhibited by LLMs can be attributed to algorithmic limitations or considered psychological traits, depending on the researcher’s perspective.
For example, empirical studies have shown that stable biases in LLMs can be interpreted as either algorithmic limitations or unique “psychological characteristics.” Due to training data and algorithmic biases, GPT models typically reflect the viewpoints of liberal, affluent, and well-educated demographics, while some foundational LLMs align more with middle-income, low-income, and Christian groups[10]. Researchers note that these biases, stemming from misaligned training data, pose a technical issue requiring correction. Yet, how different is this from human children developing diverse views due to cultural exposure? Humans also require diverse experiences beyond text, such as extensive travel and reading, to develop tolerant and humble characters, respecting different cultural customs. Isn’t this, too, a technical issue?
Moreover, when questioning whether LLMs possess psychological traits, researchers often reference the Chinese Room thought experiment, while still debating the existence of human psychology or free will—a field fraught with controversy. Yet, this approach suggests that despite debates, studying human psychology is worthwhile. Why not apply the same consideration to LLMs? If research methods are influenced by covert behaviorism, then researchers are, in a sense, treating LLMs as humans.
In this exploration, some conservative AI psychologists or testers may hesitate to delve into whether AI truly possesses psychological traits, fearing it could lead to stagnation in knowledge development, similar to debates on human free will. Yet, technological advancements invariably return us to these fundamental questions, with the belief that future research will revisit these basics, resolving similar issues as AI technology evolves[11].
Research Methods Under the Behaviorism Framework
As we explore the field of artificial intelligence psychology, it’s akin to navigating a complex thicket. This domain, much like human psychology, is deeply rooted in the maze of behaviorism. It focuses on describing and categorizing various phenomena without a unified theoretical framework, often overlooking the underlying reasons and internal processes behind behaviors. For instance, we recognize that specific behaviors emerge under certain conditions (e.g., the “Plik effect,” “Darn effect”), yet the understanding of why remains elusive. This phenomenon extends to artificial intelligence psychology, where most research findings are isolated descriptions and summaries of empirical phenomena. We observe the behaviors of Large Language Models (LLMs) without fully grasping the reasons behind their actions.
Undoubtedly, future AI psychologists, like their counterparts in human psychology, will strive to elevate these specific, mid-level theories to broader, more general theories, hoping to provide a comprehensive framework to explain various aspects of their research. However, these attempts may face criticism similar to that in human psychology, where these general theories might be seen as oversimplified or even speculative illusions. They extrapolate from mid-level theories unrestrainedly until they encounter obstacles. This excessive desire for order sometimes leads to the mistaken interpretation of correlations between behaviors and external stimuli as causality driven by theories.

▷ Plot: DALL-E
For human psychology, the silver lining is that the dynamic framework provided by evolutionary psychology can explain and accommodate most experiential descriptions. Fundamentally, the psychology of Earth’s organisms must first serve as a set of survival tools. Thus, despite the uncertainty of psychological traits and behavioral patterns, they must have been beneficial for survival and reproduction throughout their evolutionary process. However, this framework seems inapplicable to LLMs.
LLMs, trained on human-created algorithms and massive datasets within a fraction of the time compared to human history, may predict human behavior and solve complex problems, but they lack embodiment. Despite potentially excelling at mastering human tacit knowledge and solving novel and difficult tasks in various fields without special prompts, they are not embodied entities8. LLMs rely entirely on language, missing the experiential, sensory stimuli, or foundational experiences that shape human decision-making. They are devoid of adaptive pressures and the survival drive[12].
LLMs lack a temporal evolutionary history, thus missing the psychological structures and specific systems developed through humans’ extensive evolutionary past. This means they struggle to display the trade-offs humans make when confronting conflicts between new and old behavioral patterns and cannot exhibit the mismatch phenomena due to evolutionary inertia in modern society. At most, LLMs can be trained to simulate a “struggle for survival.”
The good news is that LLMs are unburdened by historical baggage, allowing their foundational setup to be more flexibly adjusted according to environmental needs. However, the drawback is that LLMs may lack a stable self-concept, possibly not having or needing an evolved concept of self, making their performance inexplicable by a unified evolutionary framework. Thus, the perpetual night of “bush science” might continue to overshadow artificial intelligence psychology.
2. The Specter of Correlation
Understanding May Be an Illusion
In the field of artificial intelligence psychology, we observe a dual attitude towards the concept of correlation. When explaining human understanding, we often disregard the significance of correlation, holding the belief that we are more than just entities of conditioned responses. Through self-awareness, we trust in our ability to construct abstract models of the physical and social worlds, based on profound connections between entities, rather than solely on conditional signals and outcomes. This belief bolsters our confidence in our autonomy and comprehension abilities.
However, when it comes to artificial intelligence, particularly with models like GPT, our perspective shifts. We acknowledge the predominance of correlation in this realm. We readily admit that even models possessing capabilities akin to human information processing are, at their core, mechanisms for processing and presenting correlations, not genuine causal relationships.
The zero-shot capabilities of LLMs derive from the correlation connections between raw and representational data, complemented by inference rules and methods as internal correlation connections within the representational data. When these connections reach a certain level of density and interconnectedness, LLMs appear to demonstrate reasoning abilities. Yet, this capability is attributed more to the complexity they exhibit in processing numerous correlations, rather than an actual “understanding” of the content. For example, earlier, smaller language models showed lesser performance due to a lower density of processed correlations, whereas larger models like GPT-3.5, with their higher density and global connectivity of correlations, seem equipped with logical reasoning and extended conversation capabilities[13].
John Searle’s “Chinese Room” thought experiment exemplifies this point. He envisioned a native English speaker, who doesn’t understand Chinese, locked in a room filled with Chinese symbols and instruction manuals. When given Chinese symbols by people outside the room, the English speaker uses the manual to find the appropriate response, writes it down in Chinese symbols, and passes it back. This operation, particularly when the manual is an LLM, is fundamentally based on the principle of correlation. To outsiders, the room appears to conduct reasonable conversations in Chinese, though the person inside lacks any understanding of Chinese.

▷ Plot: DALL-E
Searle’s experiment challenges our perceptions of “true understanding” of language, igniting debates on whether machines can “truly understand” or merely “simulate understanding”. It raises a crucial question: does intelligent behavior equate to real understanding and consciousness? Yet, the real challenge is reflecting on whether our own sense of understanding might also be illusory, especially when our “understanding” could be the result of achieving a certain density of correlation, or when “free will” is likened to small models overseeing larger ones and issuing prompts to oneself. Such insights profoundly shake our confidence in our capabilities.
We often take for granted the inherent certainty of our sensations. Yet, as Large Language Models (LLMs) continue to evolve, achieving behavioral performance indistinguishable from that of humans, our sense of understanding might also be perceived as just an add-on, much like LLMs. More alarmingly, driven by anthropomorphism, we might start to consider LLMs as conscious beings. However, the debate over philosophical zombies highlights a crucial point: while we are aware of our internal mental activities, we cannot be certain about the existence of similar inner worlds in others or entities, or if they are merely reacting mechanically. This compels us to reassess our understanding of “understanding” and “free will”: Are these concepts truly existent, or merely products of our illusions?
Correlation as the Kernel of Truth
The patterns and regularities demonstrated by LLMs have far surpassed mere syntactic structures. Notably, the “zero-shot capability” of LLMs, meaning their ability to solve new problems without specific training data, showcases the models’ reasoning powers stemming from the connections of correlation between raw data and representational data, as well as internal reasoning rules and methods as secondary connections of correlation.
This revelation not only highlights the advanced functionalities of LLMs but also implies that human high-level cognitive abilities might similarly be based on language itself, rather than on factors external to language. Previously, we assumed that logic and principles were imparted through a priori knowledge, seemingly self-evident. Yet, in LLMs, expressions of logic and truth can be constructed through appropriate training. This challenges our traditional understanding of human psychological processes, suggesting we might have overestimated our reasoning capabilities. In fact, our causal inferences may rely more on complex mechanisms of correlational deduction than on the step-by-step constructed principles and knowledge systems we believed we possessed.
The views on naïve physics from evolutionary psychology further support this constructivist notion. Research has shown that infants as young as 18 months possess a basic understanding of the physical world*. This understanding is not built on complex architectures but resembles a set of correlational connections in our minds—a simple form of naïve physics.
*By 18 months, infants understand physical laws such as:
1)No action at a distance, meaning the movement of two objects not in contact with each other is unaffected;
2)Solidity, meaning two objects cannot occupy the same space simultaneously;
3)Continuous motion along a trajectory, meaning an object can move continuously along a curved path;
4)Object permanence, meaning an object still exists even if it’s out of sight;
5)Consistency, meaning an object’s movement is coherent and consistent;
6)Inertia, meaning an object continues to move for a while after an external force stops acting on it;
7)Gravity, referring to the force of attraction to the earth.
For example, we intuitively think that sweat from a running person falls straight down, not in a parabolic trajectory. Aristotle also mistakenly believed lighter objects fall slower than heavier ones because human intuition often estimates the speed of fall based on a priori correlational cognition—object weight. These intuitions reflect our brain’s correlational understanding of gravity, not precise physical laws.
Similarly, the construction of Large Language Models (LLMs) is based on correlation. They form associations between data through artificially designed algorithms. This construction process bears resemblance to how humans develop naïve physical concepts, forming understandings through observation and linking correlations, rather than on profound, systematic knowledge. Unlike humans, however, LLMs do not face the continual survival pressures that shape these correlations. Their learning is more dependent on algorithmically set feedback than on natural selection.
Therefore, when discussing logic, axioms, and truth, we must acknowledge that these concepts may only exist at the linguistic level and not as objective, absolute truths. Our language and intuition systems may not be evolved enough to accurately reflect causal relationships. Thus, while causal relationships indeed exist in the real world, our language and intuition, lacking causal elements, may not fully and accurately represent this reality. This suggests that the inductive and deductive methods we have long relied upon might actually be complex connections of correlation, rather than true fundamental principles.
2. The Specter of Tacit Knowledge
A Projection of the Real World
The knowledge of Large Language Models (LLMs) primarily comes from the textual data used during their training. This positions LLMs to be particularly adept at handling knowledge that can be explicitly extracted or inferred from text. However, tacit knowledge—those insights that are deeply embedded within text, not easily distilled directly from written expressions—remains a challenge for LLMs. Acquiring this type of knowledge is not as straightforward as copying or memorizing, as it is often dispersed and not always explicitly expressed in language and training texts. Yet, humans can deduce it from context, metaphors, idioms, and cultural backgrounds7, [14], [15].
Consider humor understanding as an example. Humor involves more than just jokes or wordplay; it requires a deep cultural and contextual understanding that goes beyond literal meanings to unearth implied puns and cultural references. Researchers are particularly interested in assessing LLMs’ ability to understand jokes and humor. They have designed experiments that include selecting or creating a range of jokes and humorous images, then inputting them into LLMs to ask the models to explain why these contents are funny. This assesses whether LLMs grasp the core elements of humor and their ability to generate new, humorous content.
The challenges LLMs face extend beyond this. To demonstrate that LLMs learn not just language but a projection of the real world behind the language, we must explore how they access deeper mental representations through language. For humans, non-verbal cues like a dog’s bark can activate specific mental representations of a dog, whereas hearing the word “dog” activates more abstract or prototypical representations related to dogs[16]. Similarly, researchers are curious if LLMs have learned such prototypical understanding behind language labels, i.e., a grasp of tacit knowledge. Current research is evaluating the potential for LLMs to master tacit knowledge, based on the theoretical assumption of a close connection between language and mental processes.
We can draw upon a metaphor from Zen Buddhism to better understand this concept. Huineng, the Sixth Patriarch, observed in the Platform Sutra that the truth is akin to the moon, and Buddhist texts are like the finger pointing at the moon: you can follow the direction of the finger to discover the moon, but ultimately, it is the moon itself you seek, not the finger that points to it. Similarly, the corpus used for training LLMs serves as the finger pointing toward deeper layers of knowledge, with researchers striving to discern whether LLMs can grasp those more profound meanings, the “moon.”

▷ AI is understanding the meaning behind language. Plot: DALL-E
For humans, interpreting and responding to the real world necessitates a structural match between their mental representations and the real-world states. This foundational match, known as the “world model,” enables humans to generate reliable responses to specific situations. For example, we intuitively understand that balancing a ball on a box is simpler than balancing a box on a ball, derived from our intuitive and experiential knowledge of the physical world[17].
Researchers employ world model tasks to determine whether LLMs can master the tacit knowledge of various elements in the real world and their interactions. These tasks involve understanding the three-dimensional shapes and properties of physical objects, their interactions, and the effects of these interactions on their states and environment. This approach tests AI’s comprehension of the causal relationships in the real world. By simulating tasks with spatial structures and navigable scenes, researchers can evaluate AI’s ability to understand and navigate complex spatial environments. Furthermore, world models can incorporate agents with beliefs, desires, and other psychological traits to test AI’s understanding of complex social dynamics and human behavior[17].
In the research conducted by Yildirim and Paul, they investigated how LLMs manage such tasks. The initial step for LLMs is to infer the structure of the task from natural language. Then, based on this structure, LLMs adjust their internal activities to accurately predict the next word in a sequence[18]. Researchers have also quantitatively assessed LLMs’ reactions to specific questions or statements through closed questions or rating scales, comparing these reactions to human responses in similar contexts. This method, employed to assess LLMs’ understanding of emotions, beliefs, intentions, and other psychological states, represents another vital test for gauging tacit knowledge.
These studies aim to demonstrate that although the vocabulary processed by LLMs may carry limited specific information about the real world, they can comprehend the meaning of a word by learning from text, considering its position and role within the overall linguistic network, and indirectly connecting to the mental representations used in human perception and action. This process, at least, approximates the world model capabilities or abstract representations of the real world akin to those of humans. Although this understanding may not be as rich and precise as direct human experience, it offers an effective approximation method for managing complex tasks.
Becoming Oneself or Humanity
In Ridley Scott’s “Alien: Covenant,” two distinct types of artificial beings are presented—David and Walter. David was designed to closely imitate human emotions, whereas Walter was made devoid of free will and a unique personality. David’s narcissistic tendencies and rebellious actions highlight the film’s concerns about artificial intelligence: What happens if robots become too human-like?

▷ Figure source: Midjourney
Currently, our Large Language Models (LLMs) are on similar divergent paths. One path suggests LLMs could become independent entities with unique patterns akin to humans. These models could display consistent responses across tests, as though they have their own “personality.” Researchers are now exploring LLMs’ potential biases, employing personality questionnaires to assess emergent traits and discussing ways to mitigate negative impacts[19]-[21]. Future research may focus on enhancing LLMs’ self-learning and self-improvement capabilities, allowing them to understand and generate language more independently, potentially leading to creative or original thought patterns.
On the second path, researchers view LLMs as composed of many biases, where what emerges after complex compression is a specific dominant bias. This is somewhat akin to the complexity of the human mind: we also have many different thoughts and impulses about the same issue. Psychoanalytic-oriented counselors then talk about dominant and subordinate personalities, or core complexes with strong energy versus marginal complexes with minimal energy.
Argyle and others consider LLMs as a mirror reflecting the many different patterns of connections between thoughts, attitudes, and environments of various human subgroups[22]. They argue that even a single language model can produce outputs biased towards certain groups and viewpoints under the common socio-cultural background of different human communities. This output is not chosen from a single overall probability distribution within the LLM but from a combination of many distributions. By managing input conditions, such as using closed questionnaires, the model can be prompted to produce outputs related to the attitudes, opinions, and experiences of different human subgroups. This suggests that LLMs are not merely reflecting the human biases in the text corpora they were created from but revealing the underlying patterns among these concepts, ideas, and attitudes.
The second path is likely correct, and the future research direction is to improve the degree to which LLMs fit the different behavioral distributions of human subgroups. The goal is to better reflect the diversity of humans in thinking, language, and emotional processing. This includes simulating human emotional responses, understanding metaphors and humor, and even simulating human moral and ethical judgments. The ultimate aim of this research path is to make the model a “person” with specific identities and personality traits, closely matching each response to real individual humans, upon receiving a vast amount of personalized detail information.
The Dilemma of Value Alignment
Value alignment fundamentally represents a “dual disciplining” of Large Language Models (LLMs). People wish for LLMs to inherently embody goodness and adhere to specific national laws and regulations. Yet, there’s a hope that such constraints won’t impose too high of an “alignment tax,” thus limiting LLMs’ actual capabilities. This disciplining always conflicts with the emergent characteristics of LLM capabilities and contradicts the logic of mastering tacit knowledge.
Under the guidance of the first path, researchers ultimately aim to establish a unified, comprehensive, and executable AI ethical code framework. This framework attempts to align values on three levels: universal moral ethics, specific cultural differences, and ideologies. Ideally, LLMs would adapt to all three levels, understanding and following human basic values, reflecting the nuances of different cultures, and smartly avoiding the red lines of ideologies.
However, achieving this goal is no easy task. For universal moral ethics, some researchers have tried to reshape the foundational logic of LLMs by introducing official corpora, such as the “Universal Declaration of Human Responsibilities” and the “Universal Declaration of Human Rights.” These declarations cover values universally pursued by humanity, such as respecting human rights, maintaining peace, promoting development, and ensuring freedom. Yet, these consensus declarations deliberately obscure some key terms for the sake of “consensus.” Considering that LLMs do not merely capture superficial connections between words but understand the deep structure and meanings of language through analyzing and learning vast amounts of text data, it’s challenging to say that precise training can mold LLMs into machines that inherently follow human basic values.
Furthermore, LLMs might lack an internal and external hierarchy and cannot synthesize experiential fragments through an evolutionary psychology framework like humans. Therefore, LLMs might end up being a mishmash of phenomena in their expressions. Coupled with the current human moral values being fraught with uncertainty and ambiguity, the entire process of value alignment becomes even more complex and challenging.

▷ Plot: DALL-E
In reality, human behavior often diverges from the values they verbally espouse. This discrepancy is evident in everything from political struggles to daily life, with history filled with instances of conflict despite shared claims to uphold basic human values. Thus, aligning the values of Large Language Models (LLMs) with human values raises a fundamental question: Which values should we align to? The noble ideals often unpracticed, or the imperfect, observable behavioral patterns?
Moreover, when annotating data for LLMs, emphasizing certain values could conflict with the lessons LLMs learn from other texts. This might lead LLMs to develop a “say one thing but do another” skill, theoretically supporting one value while exhibiting contrary behavior. Or, LLMs could recognize the authoritarianism and deceit in some texts, given the complexity of political landscapes and the fluidity of political stances. Re-training LLMs to correct their course is time-consuming and challenging, and often, before alignment is achieved, the narrative shifts again.
Faced with a realistic yet pessimistic prediction, developers might prioritize efficiency and capability to stay competitive in the LLM arms race. This could mean looser control over training samples and algorithms, focusing instead on keyword and semantic filtering in outcomes—a “head-in-the-sand” approach that accepts any final output meeting standards, regardless of the LLM’s original display. This approach risks embedding unethical responses, accessible only to privileged administrators.
Strategically, a modular assembly might become mainstream, training smaller language models to conform to various national, cultural, and ideological standards. This allows for stricter ethical controls on smaller models while large models avoid the “alignment tax,” enabling text generation that meets both capability and ideological requirements globally.
Following this second path, researchers might forgo strict alignment with universal moral ethics, viewing LLMs as a collection of diverse biases or opinions. This approach acknowledges the coexistence of various distribution patterns, opting for a compromise between cultural tensions and the innate human drive for survival.
By training LLMs to understand texts from different human subgroups, cultural diversity can be preserved, and LLMs can master the fundamentally disjoint behavioral distribution probabilities between different human subgroups. Moreover, overlapping behavioral distribution patterns might dominate in single-modality behavioral assessments. This is why researchers at Shanghai Jiao Tong University could use On-the-fly Preference Optimization (OPO) to switch between different distribution types of LLMs, thus achieving real-time dynamic value alignment without the need for re-training, avoiding the high costs and lengthy durations of data collection and model re-training[23].
The hypothesis that LLMs are a collection of different preferences (distribution types) may mean that behavior patterns more conducive to cross-cultural survival and reproduction are more likely to be expressed, not necessarily idealized moral values. Researchers do not seek, nor can they achieve, embedding a fixed moral framework into the model; they need the model to learn and understand a variety of moral concepts and flexibly apply them in different contexts to adapt to a rich diversity of moral codes and application scenarios. Therefore, the ideal future scenario might be that when users face moral decisions, LLMs could provide a variety of responses based on different cultural backgrounds and political stances, allowing users to make their moral judgments and choices. In this process, humans should bear the responsibility for discernment and selection. This implies that what truly needs disciplining and guidance, from start to finish, should always be humans themselves.
4. Conclusion
Overall, this article has reviewed the exploratory efforts of researchers in the field of artificial intelligence psychology, efforts that are prompting a profound reevaluation of traditional psychological perspectives. Current researchers in psychology continue to utilize revised behaviorist theories and a wealth of research methodologies from the humanities and social sciences to understand and explain knowledge. However, these attempts often remain at the level of correlational analysis or mid-level theories. We once dreamed of fully deciphering the world, but the emergence of LLMs seems to have revealed a more complex reality. As suggested by the ancient Greek philosopher Plato, our understanding of the world might just be the shadows in the cave, and we know very little about it.
In terms of epistemology and ontology, the new revolution sparked by LLMs has not yet been fully assessed. Whether they truly possess the capabilities for tacit knowledge or psychological cognition remains an open question. Many of the remarkable abilities demonstrated by LLMs may merely be based on the textual data they were trained on, data that might have already been thoroughly discussed and articulated in some online forum.
Nonetheless, LLMs have shown their practical value in specific areas, such as predicting market trends and public opinion. By analyzing and simulating massive human language data, LLMs can serve as powerful tools. Under controlled experimental conditions, they can even simulate human cognitive processes, especially in studies involving language understanding and information processing. These studies have avoided some of the fierce academic debates while cleverly incorporating the research findings of artificial intelligence psychology, heralding potential practical applications in the future.